








 Промо акции
Промо акции Сервисные контакты
Сервисные контакты Поддержка
Поддержка Демо-стенды
Демо-стенды Статусы и сертификаты
Статусы и сертификаты Выполненные проекты
Выполненные проекты 
 8 (495) 411-82-82
8 (495) 411-82-82-
8 (800) 500-82-81
 cbs@cbs.ru
cbs@cbs.ru Пн-Пт с 10:00 до 18:30
Пн-Пт с 10:00 до 18:30 109544, г. Москва, ул. Малая Андроньевская, 20/8, стр. 1-1А
109544, г. Москва, ул. Малая Андроньевская, 20/8, стр. 1-1А
Технологии виртуализации коммутаторов Cisco и Hewlett Packard Enterprise
- 25.11.2015
- 2865
Автор
Сергей Калашников, CCIE
Технический директор

Сегодня хотелось бы поговорить о двух достаточно схожих технология виртуализации коммутаторов, которые позволяют объединять несколько коммутаторов в один логический. Речь пойдёт про технологии Cisco Virtual Switching System (VSS) и HPE Intelligent Resilient Framework (IRF). В рамках статьи мы рассмотрим более подробно, как работает технология VSS, после чего поговорим о технологии IRF.
Обе технологии (VSS и IRF) позволяют нам объединять коммутаторы, используя обычные Ethernet-порты. В целом данные технологии можно отнести к технологиям стекирования. Но оба вендора стараются всё же их называть технологиями виртуализации. Cisco вообще избегает слова стек в отношении VSS.
Cisco VSS
Технология VSS позволяет объединить два физических коммутатора в один логический. Но в отличии от более классических технологий стекирования (StackWise, FlexStack) для связи коммутаторов между собой используются не какие-то специализированные кабели, а Ethernet-порты. Таким образом, коммутаторы могут находиться на относительно большом удалении друг от друга.
После объединения коммутаторы начинают работать как один логический (рисунок 1). Оба коммутатора являются активными и обеспечивают передачу пакетов. При этом управление обоими коммутаторами осуществляется одним из устройств. Другими словами, уровень обработки данных (data plane) активен на обоих устройствах. А вот уровень управления (control plane) только на одном. Вспомним, что control plane (предлагаю в дальнейшем использовать именно иностранное наименование) отвечает за логику работы коммутатора: обработку всех сетевых протоколов (L2/L3), формирование таблицы маршрутизации, заполнение таблиц CEF, ACL, QoS и т.д.
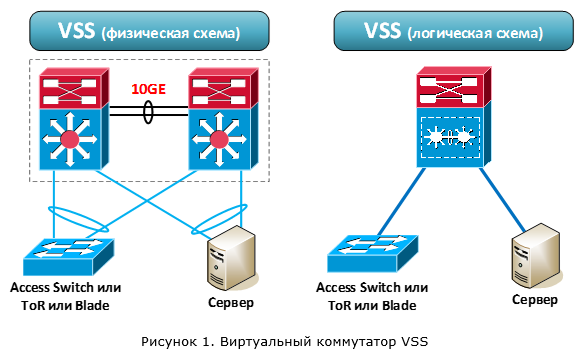
Технология VSS поддерживается на следующих коммутаторах Cisco:
- Cisco 4500E и 4500X
- Cisco 6500E и 6800
Но взять любые два таких устройства и объединить их по технологии VSS не получится. Во-первых, не на всех супервизорах, не со всеми линейными картами, а также не со всеми сервисными модулями поддерживается технология VSS. Например, для 6500E технология VSS поддерживается на супервизорах Sup720-10GE и Sup2T. Во-вторых, технология VSS работает только между одинаковыми платформами, например, между двумя 4500X или двумя 6500E+Sup2T. Набивка устройств (линейные карты и сервисные модули) может отличаться. Также может отличаться размер шасси для коммутаторов 4500E и 6500E. Нюансов много, поэтому крайне желательно посмотреть актуальные требования к железу, версиям ПО и лицензиям на сайте вендора.
После того как мы объединили два коммутатора между собой, общая производительность системы увеличивается в два раза. Это обусловлено тем, что оба коммутатора отвечают за обработку пакетов. Таким образом, мы получаем:
- до 1,6 Тбит/с для коммутаторов серии 4500X,
- до 1,8 Тбит/с для коммутаторов серии 4500E с супервизором Sup 8-E,
- и до 4 Тбит/с для коммутаторов серии 6500E/6800 с супервизором Sup2T.
Архитектура VSS представлена на рисунке 2. Один из коммутаторов выбирается основным, второй коммутатор — резервным. На основном коммутаторе control plane становится активным (Active), а на резервном переходит в состояние горячего резерва (Hot Standby).
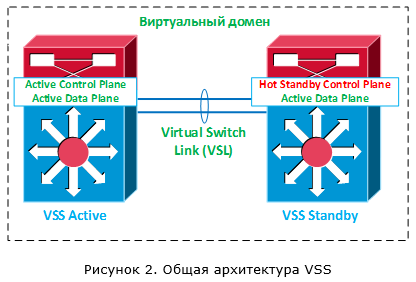
Активный control plane управляет работой обоих коммутаторов. Также в процессе работы происходит постоянная синхронизация состояния между активным control plane на основном коммутаторе и control plane на резервном коммутаторе для обеспечения отказоустойчивости. Управление и синхронизация выполняются через специальный канал – Virtual Switch Link (VSL).
Канал VSL – это прямое соединение между двумя коммутаторами (никаких промежуточных устройств не допускается). Для обеспечения VSL канала коммутаторы подключаются друг к другу через обычные Ethernet-порты. Но когда я говорю про обычные порты, я чуточку лукавлю. Как можно догадаться, к этим портам также есть определённые требования и эти требования варьируются в зависимости от платформы коммутаторов. Ко всем пакетам, которые передаются через канал VSL, добавляется специализированный заголовок – Virtual Switch Header (его длина 32 байта):

VSL может состоять из нескольких физических каналов (что собственно и рекомендуется делать). Это необходимо для отказоустойчивости нашей системы, а также получения необходимой пропускной способности. Агрегация осуществляется с помощью протоколов PAgP или LACP. Т.е. максимально мы можем иметь 8 активных каналов, объединённых в один логический VSL. Например, если мы используется порты 10 Гбит/с, мы получим до 80 Гбит/с при агрегировании 8 таких каналов.
Я думаю, многие заметили, что VSL канал является аналогом стековой шины. Поэтому очень интересно посмотреть на трафик, который предаётся через него:
-
управляющий трафик системы (трафик протоколов, обеспечивающих работу виртуального коммутатора VSS, в том числе синхронизацию состояния между коммутаторами),
-
сетевой управляющий трафик (трафик, адресованный control plane, но полученный резервным коммутатором: CDP, VTP, STP, EIGRP/OSPF и т.д.),
-
пользовательский трафик (в том числе, широковещательный и многоадресный),
-
сервисный трафик (например, SPAN).
В процессе обсуждения мы так или иначе остановимся более подробно на каждом типе трафика.
Итак, после того, как запустились коммутаторы, в бой идут протоколы, обеспечивающие начальную инициализацию VSS:
- Link Management Protocol (LMP)
- Role Resolution Protocol (RRP)
Протокол LMP проверяет, что канал VSL поднялся и устройства видят друг друга. Протокол RRP проверяет аппаратную и программную совместимость устройств, а также определяет, кто будет основным коммутатором, а кто резервным.
Control plane на основном коммутаторе выполняет две функции. Первая – обеспечивает логику работы коммутатора: программирование коммутатора на основании конфигурации, обработку всех сетевых протоколов (L2/L3), формирование таблицы маршрутизации, таблиц CEF, управление портами и т.д. Вторая функция – заполнение всех аппаратных таблиц (FIB, Adjacency, ACL, QoS и т.д.) на обоих коммутаторах для обеспечения обработки пользовательского трафика (на аппаратном уровне). Control plane на резервном коммутаторе находится в состоянии горячего резерва. При этом состояние активного сontrol plane постоянно синхронизируется с резервным. Это необходимо для того, чтобы обеспечить беспрерывную работу нашего виртуального коммутатора в случае отказа основного физического коммутатора.
Синхронизируется следующая информация: параметры загрузки устройств, их конфигурация, состояния сетевых протоколов и различных таблиц (запущенных на активном control plane), состояние устройств (линейных карт, портов).
Передача управляющих данных и синхронизация состояния между основным и резервным коммутаторами, выполняется с помощью специализированных протоколов:
-
Serial Communication Protocol (SCP) – обеспечивает связь между процессором и линейными картами (как локальными, так и на удалённом коммутаторе)
-
Inter-process Communication Packets (IPC) – обеспечивает связь между процессорами распределённых устройств
-
Inter-Card Communication (ICC) – обеспечивает связь между линейными картами
Все эти протоколы относятся к управляющему трафику системы, который передаётся между коммутаторами по VSL каналу и образуют логический канал управления (Inter-Chassis Ethernet Out Band Channel – EOBC).
За синхронизацию состояния между коммутаторами отвечает механизм переключения с сохранением состояния (Stateful Switchover — SSO). Данный механизм появился достаточно давно. Например, он используется для резервирования супервизоров в рамках одного коммутатора 6500. Он же используется и в технологии VSS (придумывать что-то новое не стали). Но как мы помним, SSO не позволяет синхронизировать состояние протоколов маршрутизации. А значит при переключении на резервный коммутатор протоколы динамической маршрутизации запускаются с нуля. Что автоматически обрывает все L3-соединения с удалёнными устройствами. Т.е. мы получаем временную потерю связи с внешним миром. Для решения данной проблемы технология SSO работает в связке с технологией Non-Stop Forwarding (NSF). Данная технология выполняет следующие задачи: обеспечивает передачу пакетов L3 в момент переключения (по факту замораживает старые записи о всех маршрутах), оповещает удалённые маршрутизаторы о том, что не нужно рвать связь, а также запрашивает у них всю необходимую информацию для построения новой таблицы маршрутизации. Конечно, же удалённые устройства должны в этом случае также поддерживать технологию NSF (так сказать, быть NSF-aware).
Кстати, для справки: резервному коммутатору требуется до 13 секунд, чтобы полностью перезапустить процесс динамической маршрутизации. Поэтому без технологии NSF было бы совсем грустно.
А как быстро произойдёт переключение на второй коммутатор в случае отказа первого? Вендор на этот счёт приводит среднюю цифру 200 мсек. Для 6500E (видимо и для 6800 тоже) в ряде случаев она может достигать 400 мсек (так сказать, издержки распределённости архитектуры).
Что касается control plane стоит отметить ещё один момент. Так как активным control plane является только на одном из коммутаторов, весь трафик сетевых протоколов обрабатывается именно им. Например, трафик протоколов динамической маршрутизации (OSPF, EIGRP, пр.) должен в конечном итоге попасть на активный control plane. А значит, если он сначала попал на резервный коммутатор, этот трафик будет передан на основной коммутатор через VSL канал. При этом ответные пакеты могут быть отправлены напрямую с основного коммутатора (приоритетный вариант), а могут быть переданы через резервный. Это зависит от нескольких вещей: типа сетевого протокола и наличия прямого канала от основного коммутатора до получателя.
Если мы имеем дело с коммутаторами 4500E/6500E/6800, мы можем в каждый из них установить по два супервизора (так сказать, задублируем задублированное). VSS поддерживает и такую конфигурацию (называется она Quad-Supervisor). Это нужно в том случае, когда мы не хотим терять общую производительность системы, в случае выхода из строя одного из супервизоров. Для всех вариантов кроме Sup2T, второй супервизор в шасси работает в холодном резерве (Route Processor Redundancy). А это значит, что второй супервизор переходит в рабочий режим (становится резервным в разрезе VSS) только после перезагрузки всего шасси. В случае Sup2T, второй супервизор в одном шасси работает в режиме SSO и никакая перезагрузка не требуется.
Теперь давайте поговорим о передаче пользовательского трафика через виртуальный коммутатор VSS. Всё-таки это его главная задача. Одна из основных причин использовать VSS – возможность агрегации нескольких каналов, приходящих на разные коммутаторы (в терминах Cisco – Multichassis EtherChannel (MEC)). Речь идёт о подключении к виртуальному коммутатору внешних устройств (например, других коммутаторов).
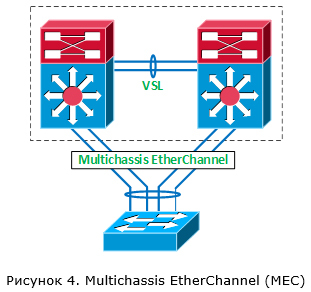
Когда мы агрегируем несколько каналов в один логический в рамках VSS, может использоваться один из протоколов динамической агрегации (PAgP или LACP) или же статический EtherChannel (режим ON). За распределение трафика внутри логического канала отвечает механизм на базе хеш-функции. Хеш-функция применяется к определённым полям заголовков, передаваемого трафика. Например, хеш-функция может применяется к значению IP-адреса отправителя. В этом случае, если у нас агрегируется два канала, то по первому каналу будут передаваться потоки трафика, у которых IP-адреса отправителя чётные, а по второму — нечётные. Это позволяет распределять потоки трафика между разными каналами, объединёнными в один etherchannel. В более сложных вариантах на принятие решения о выборе канала могут влиять сразу несколько параметров (например, Src IP + Dst IP + Src Port + Dst Port).
В случае VSS всегда работает следующее правило: в первую очередь для передачи трафика внутри MEC используются локальные каналы связи (рисунок 5). Это сделано для того, чтобы не нагружать VSL канал. Замечу, что это утверждение для 6500E/6800 справедливо, как для случая MEC, так и для случая Equal Cost Multipath (если связность между виртуальным коммутатором и соседним устройством идёт по отдельным L3 каналам).
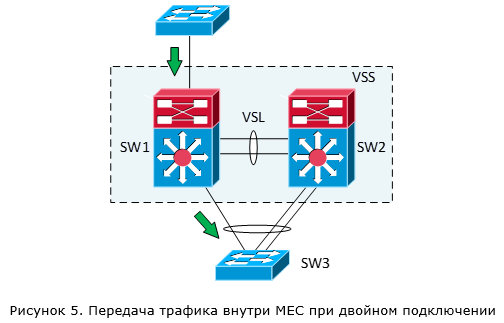
Причём не важно какая у нас общая пропускная способность каналов для каждого коммутатора. В нашем примере, даже имея двойную связь между SW2 и SW3, пакеты, поступившие на SW1 и адресованные получателям за SW3, всегда будут уходить через единственный локальный порт. Но если эта связь нарушится (или же изначально коммутатор SW3 был подключен только к SW2), весь трафик пойдёт через VSL канал (рисунок 6).
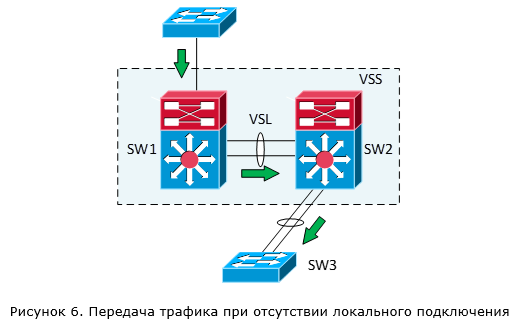
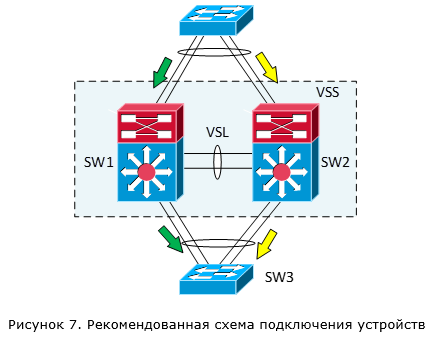
Отсюда делаем вывод, что рекомендованная схема работы VSS – это подключение устройств одновременно к обоим коммутаторам VSS (рисунок 7). В этом случае у нас трафик будет распределяться между обоими коммутаторами VSS и мы получим увеличение производительности всей системы практически в два раза по сравнению с одним коммутатором. В противном случае мы нагружаем VSL канал и теряем в суммарной производительности системы (расходуя на обработку одного потока трафика мощности обоих коммутаторов).
Для улучшения работы механизмов балансировки трафика внутри каналов MEC для технологии VSS были добавлены следующие функции:
Адаптивное распределение хеша – при добавлении и удалении каналов система старается сохранить потоки трафика на тех же каналах, где они были.
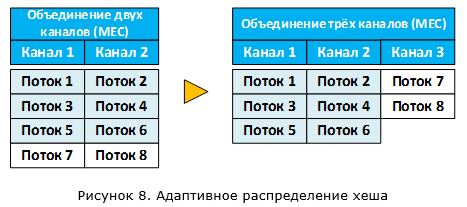
В нашем примере (рисунок 8) при добавлении третьего канала, будут затронуты только 7 и 8-й потоки трафика.
Расширены варианты балансировки трафика между каналами (например, может использоваться номер VLAN), а также используется дополнительный псевдослучайный идентификатор Unique ID. Всё это добавлено для предотвращения эффекта поляризации трафика (когда трафик в основном передаётся только по определённым каналам, недозагружая другие).
Для того чтобы закончить с пользовательским трафиком, хотел бы отметить ещё один момент. Через канал VSL будет также передаваться трафик, который рассылается всем устройствам внутри VLAN. К такому трафику можно отнести широковещательный трафик, трафик для которого нет данных о MAC-адресе получателя (unknown unicast) и multicast-трафик.
Итак, мы выяснили что оба коммутатора обрабатывают трафик, при этом всё управление сосредоточено на одном из них. В качестве общей соединительной шины используется канал VSL, через который происходит передача как минимум управляющей и синхронизирующей информации. Через этот же канал резервный коммутатор узнаёт, что основной коммутатор «умер». Но что будет если этот канал разорвётся, при этом оба коммутатора будут исправными? Ответ прост, основной коммутатор останется активным, а вот резервный коммутатор посчитает, что его коллега отказал, и соответственно тоже станет активным (везде речь про control plane). А так как конфигурация у этих коммутаторов одна, мы получим в сети два абсолютно одинаковых устройства с идентичной адресацией. Думаю, не стоит говорить, к чему это приведёт. Для того чтобы избежать такой ситуации, как минимум не стоит разрывать VSL канал. Но не всегда это от нас зависит, поэтому есть механизм, который позволяют минимизировать последствия разрыва VSL канала. Данный механизм использует один из трёх методов обнаружения сбойной ситуации:
- Enhanced PAgP
- Fast Hello
- IP BFD
После того как будет определено, что оба коммутатора стали активными в следствии обрыва канала VSL, выполняются следующие действия:
-
Коммутатор, который был активным до того, как разорвался VSL канал, отключает все интерфейсы, кроме VSL и интерфейсов, для которых в ручном режиме указано, что их не нужно отключать. Такое поведение позволяет сети продолжать работать дальше, правда на одном коммутаторе, зато без коллизий.
-
Как только VSL канал будет восстановлен, коммутатор, который был изначально активным, перезагрузится. После перезагрузки он станет резервным.
Таким образом, при наступлении ситуации с двумя активными коммутаторами в конечном итоге активным остаётся тот, который был изначально резервным. Давайте посмотрим, как работает каждый из озвученных методов.
В случае работы Enhanced PAgP (прим. PAgP – проприетарный протокол) в качестве «лакмусовой бумажки» используется внешнее устройство. Каждый коммутатор VSS рассылает специальное сообщение PAgP через локальные порты в рамках одного логический канала MEC, через который подключен внешний коммутатор (рисунок 9). В таком сообщении содержится идентификатор активного коммутатора VSS. Получив ePAgP пакет, удалённое устройство его отправляет в обратную сторону. Если у нас всё хорошо, оба коммутатора отсылают один и тот же идентификатор активного коммутатора VSS. Если же оба коммутатора стали активными, каждый из них будет отсылать сообщения с собственным идентификатором (рисунок 10). А так как удалённое устройство отправляет такие сообщения обратно, оба коммутатора поймут, что наступила сбойная ситуация.
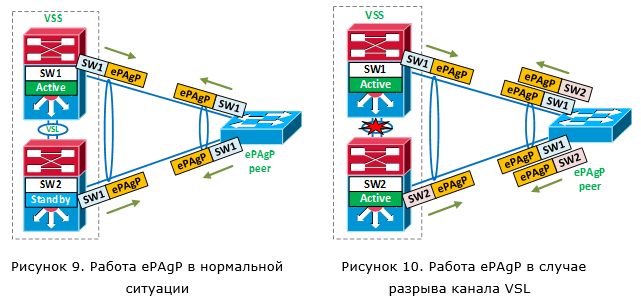
А как быстро обнаружится сбойная ситуация в этом случае? Как только коммутатор, который изначально был резервным, становится активным, он сразу же отсылает сообщение ePAgP со своим идентификатором. Таким образом, время обнаружения сбойной ситуации – доли секунд. Безусловно удалённое устройство также должно поддерживать ePAgP. Такая поддержка есть на коммутаторах 2960, 3750 (но не в стеке) и пр.
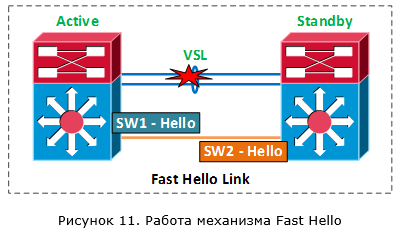
Следующий механизм — Fast Hello. В этом случае между коммутаторами VSS делается дополнительный прямой L2 канал (без промежуточных устройств). В рамках этого канала коммутаторы обмениваются сообщениями VSLP Fast Hello. И если VSL канал упал, но при этом пакеты VSLP Fast Hello продолжают ходить, у нас наступила сбойная ситуация. Время обнаружения сбойной ситуации – доли секунд (VSLP Fast Hello сообщения при падении VSL канала передаются с интервалом в 200 мсек).
Последний механизм обнаружения — IP BFD (Bidirectional Forwarding Detection). Данный механизм очень похож на работу Fast Hello, но более медленный (время обнаружения исчисляется секундами). Он может работать через прямой канал L3. Данный механизм не рекомендуется использовать из-за его медленности. Более того в последних релизах IOS он отсутствует.
Рекомендуется использовать одновременно два механизма обнаружения сбойной ситуации (обрыва VSL канала).
И так, в целом основные моменты работы технологии Cisco VSS нами рассмотрены. Остался небольшой штрих – рекомендованный дизайн использования VSS. Рассмотрим два варианта:
-
Для связи с другим оборудованием использовать несколько L3 каналов
-
Для связи с другим оборудованием использовать один L3 канал поверх агрегированного логического MEC
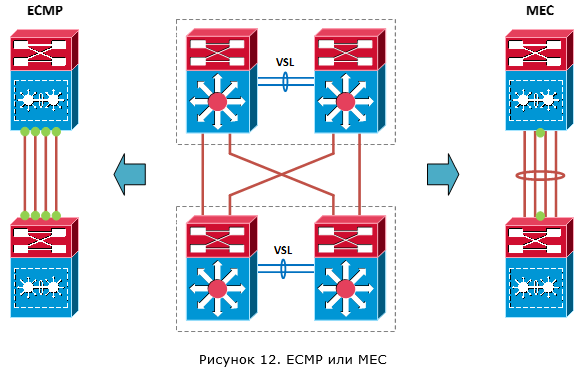
В первом случае отработка обрыва канала или отказа активного коммутатора VSS будет происходить средствами протокола динамической маршрутизации. При этом, так как мы будем иметь несколько равноценных маршрутов (по маршруту на каждый L3 канал), общая пропускная способность будет агрегироваться за счёт Equal Cost Multipath (ECMP). Собственно, ECMP и будет отвечать за распределение трафика по коммутаторам VSS. Во втором случае отработка обрыва канала или отказа активного коммутатора VSS будет отрабатываться аппаратно за счёт работы Multichassis EtherChannel. Благодаря средствам балансировки трафика между каналами (хеш функций) MEC будет отвечать также и за распределение трафика по коммутаторам VSS.
Сразу видны преимущества MEC по отношению к ECMP. У нас меньше логических связей с соседом (всего одна связь), меньше таблица маршрутов (от одного соседа мы принимаем всего одну копию маршрутов) и меньше нагрузка в случае отказа одного из каналов (по факту её нет, так как логический канал даже при потере одного физического будет продолжать работать). Плюс, для понимания такая конфигурация более простая.
А как же обстоят дела со временем переключения? Для unicast-трафика в обоих вариантах это время одинаковое. А вот для multicast, нет. В случае multicast-трафика время сходимости сети для ECMP существенно больше.
Из всего этого вывод: рекомендуется использовать вариант подключения с одним логическим соединением (MEC).
Хотел бы кратко затронуть ещё одно решение, которое использует в своей основе технологию VSS. Это решение — Cisco Catalyst Instant Access. Идея заключается в том, чтобы получить один большой виртуальный коммутатор внутри сети.
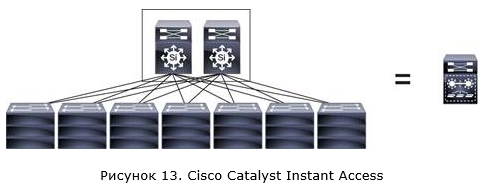
В этом случае в ядро сети (Instant Access parent) ставятся два коммутатора 6500E/6800 с супервизорами Sup2T и специализированными линейными платами, которые объединяются с помощью технологии VSS. В качестве коммутаторов уровня доступа (Instant Access client) используются коммутаторы Cisco 6800ia или 3560CX (их может быть до 42). Стоит отметить, что коммутаторы IA clients не имеют функций локальной коммутации и абсолютно все пакеты будут передаваться на коммутаторы ядра (IA parent). Правда, цена таких коммутаторов, как мне кажется, не совсем соответствует их функциональности. Но это отдельный разговор.
Пример реализации технологии VSS
Настроить технологию VSS достаточно просто. Начиная с версии Cisco IOS XE 3.6.0E (IOS 15.2(2)E) для объединения двух коммутаторов в один виртуальный можно использовать упрощённую схему настройки — Easy VSS. Два коммутатора соединяться друг с другом и должны быть видны на уровне L3. Далее вводится команда конвертации в VSS режим на том коммутаторе, который у нас будет основным:
SwitchA# switch convert mode easy-virtual-switch
Указываются порты, которые будут образовывать VSL канал (коммутаторы должны быть уже соединены друг с другом через эти порты):
SwitchA(easy-vss)# VSL Te1/1/15 Te1/1/16
После этого оба коммутатора перезагрузятся для перехода в режим работы VSS. На этом минимальная настройка закончена.
Если мы настраиваем VSS классическим способом, фактически схема не сильно усложняется. На обоих коммутаторах мы настраиваем следующее:
-
Виртуальный домен (Virtual Switch Domain) и номер коммутатора в нём:
SwitchA(config)# switch virtual domain 2
SwitchA(config-vs-domain)# switch 1SwitchB(config)# switch virtual domain 2
SwitchB(config-vs-domain)# switch 2 -
VSL Port Channel:
SwitchA(config)# interface port-channel 1
SwitchA(config)# switchport
SwitchA(config-if)# switch virtual link 1
SwitchA(config-if)# no shutdownSwitchB(config)# interface port-channel 2
SwitchB(config)# switchport
SwitchB(config-if)# switch virtual link 2
SwitchB(config-if)# no shutdown -
Добавляем физические порты в созданный PortChannel для VSL канала:
SwitchA(config)# interface range tengigabitethernet 1/15-16
SwitchA(config-if)# channel-group 1 mode onSwitchB(config)# interface range tengigabitethernet 1/15-16
SwitchB(config-if)# channel-group 2 mode on -
Запускаем конвертацию на обоих коммутаторах в режим VSS:
SwitchA#switch convert mode virtual
SwitchB#switch convert mode virtual
После того, как коммутаторы перейдут в режим VSS, в конфигурацию автоматически будут добавлены настройки параметров QoS для VSL канала. Дополнительно (опционально) мы можем настроить функции обнаружения ситуации с двумя активными control plane, в случае разрыва канала VSL. А также задать MAC-адрес виртуального коммутатора (по умолчанию он задаётся динамически).
Давайте теперь посмотрим, что мы получим после объединения коммутаторов на примере Cisco 4500X:

Первый коммутатор у нас стал основным/активным (VSS Active, id = 1), а второй – резервным (VSS Standby, id = 2). Control plane первого коммутатора стал активным (Control Plane State = ACTIVE), а control plane второго — резервным (Control Plane State = STANDBY), в режиме горячий резерв (Current Software state = STANDBY HOT (switchover target)). Для обеспечения отказоустойчивости у нас используется механизм SSO (Operating Redundancy Mode = Stateful Switchover). Также мы видим, что data plane на обоих коммутаторах находится в активном состоянии (Fabric State = ACTIVE).
Следующая информация показывает, какие порты у нас используются под VSL канал:
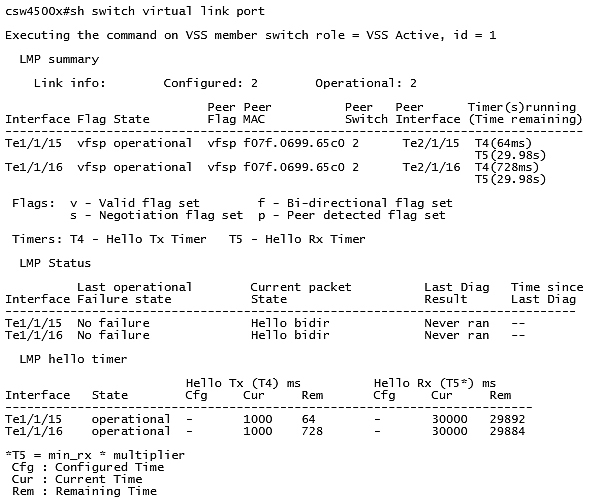
Как мы видим, порты Te1/1/15 и Te1/1/16 используются под VSL канал. Между коммутаторами запущен протокол LMP. Через оба порта по средствам протокола LMP мы видим второй коммутатор (Hello bidir).
На этом обсуждение работы Cisco VSS предлагаю завершить и перейти к решению HPE IRF.
HP Enterprise IRF
Про решение HPE IRF можно рассказать не так подробно, как про Cisco VSS. Это обусловлено тем, что информации по этой технологии не так много и чаще всего она носить достаточно поверхностный характер. Хотя может быть это и к лучшему, так не нужно «убивать» мозг в попытке разобраться с деталями. С другой же стороны не покидает чувство, что ты работаешь с неким чёрным ящиком.
В целом, если мы говорим про два коммутатора HPE, объединённые в стек (вендор допускает это определение), работа IRF и VSS очень похожа. Один из коммутаторов выбирается основным (Master), второй становится ведомым (Slave). Обработкой трафика занимаются оба коммутатора (т.е. data plane активен на обоих устройствах). Управление осуществляется основным коммутатором (на нём будет активным control plane), при этом его состояние синхронизируется с ведомым.
В качестве «стековой шины» используются обычные Ethernet-порты. На некоторых моделях для этого можно использовать даже порты 1 Гбит/с, но в большинстве случаев требуются порты минимум 10 Гбит/с. Между коммутаторами делается IRF канал (аналог VSL канала). Всем пакетам добавляет дополнительный заголовок (IRF tag).
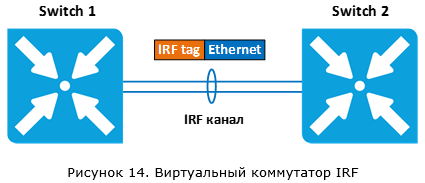
Так как текущее состояние control plane синхронизируется между коммутаторами внутри стека, отказ основного коммутатора не приводит к остановке трафика. Такое поведение аналогично работе Cisco SSO. В отличии от Cisco VSS, синхронизация включает в том числе и состояния протоколов маршрутизации. А так как переключение занимает достаточно короткое время (вендором заявлено 50 мсек), соседние устройства не успевают обнаружить отказ одного из коммутаторов и разорвать L3-соединения. Поэтому аналог технологии Cisco NSF не требуется.
Также как в технологии VSS, стек IRF поддерживает агрегацию каналов, подключенных к разным коммутаторам стека. Для обеспечения согласования параметров логического канала используется протокол LACP.
Что касается временных показатель, у технологии IRF они выглядят очень неплохо. Например, отмеченные выше 50 мсек являются не средним значением, а максимальным. В ряде документов указано, что по факту переключение произойдёт быстрее. Тоже самое касается времени переключения потоков трафика в случае добавления/удаления физических каналов в рамках агрегации в один логический. Приводится значение — 2 мсек. У Cisco это значение — 200 мсек. При таких временных показателях никакие адаптивные функции хеш и не требуются.
В случае, если у нас разорвётся IRF канал и оба коммутатора решат, что нужно стать активными, IRF работает по сходному алгоритму с Cisco VSS. Один из коммутаторов сохраняет свою роль основного, второй коммутатор переходит в состояние восстановления (Recovery-state). В этом состоянии он отключает все порты кроме IRF и тех портов, для которых в ручном режиме указано, что их не нужно отключать. Как только IRF канал будет восстановлен, коммутатор, который был в состояние восстановления, перезагрузится. После перезагрузки он станет ведомым (Slave).
Схемы обнаружения данного состояния (Multi-active detection) также очень похожи на те, которые мы рассмотрели в Cisco VSS. HPE IRF поддерживает следующие варианты:
-
LACP MAD (работа аналогична Cisco Enhanced PAgP)
-
BFP MAD (работа аналогична Cisco IP BFP)
-
ARP MAD (используется Gratuitous ARP, содержащий идентификатор активного устройства)
-
ND MAD (используются пакеты NS протокола Neighbor Discovery в рамках IPv6)
HPE рекомендует использовать LACP или BFP MAD, так как именно эти механизмы самые быстрые. ARP и ND MAD более медленные и требуются использования STP (что является чуточку неожиданным). Кстати сказать, механизмы используют разную логику выбора того коммутатора, который останется основным (мастером), поэтому HPE не рекомендует их использовать совместно (а именно LACP вместе с остальными).
Теперь давайте, посмотрим, чем HPE IRF отличается от Cisco VSS.
Во-первых, технология IRF поддерживается на более широком модельном ряде коммутаторов. Фактически это основная технология стекирования, которая есть и на относительно дешевых коммутаторах A3100 и на дорогих модульных 12900. В стек можно объединять коммутаторы только одного модельного ряда, правда, с небольшим исключением (совместно будут работать коммутаторы серии 5800 и 5820, а также 5900 и 5920).
Во-вторых, технология IRF позволяет объединить в стек до девяти коммутаторов (для ряда моделей это значение ограничено четырьмя). Возможны две топологии подключения коммутаторов в рамках IRF: шина и кольцо.
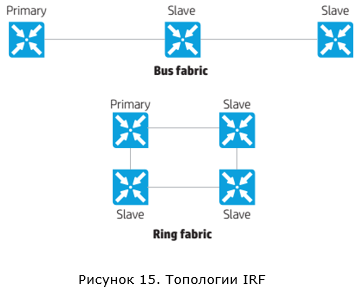
Вариант с подключением в виде кольца является рекомендованным, так как он более отказоустойчивый. При обрыве одного соединения мы не получим ситуации с двумя активными IRF группами коммутаторов.
Судя по описанию технологии, после того, как коммутаторы объединились в стек IRF, они начинают обмениваться некими hello-пакетами для построения общей топологии стека. Далее на основании этой топологии происходит передача пакетов внутри стека IRF. К сожалению, более детальной информации найти не удалось.
Прежде чем завершить обзор IRF, нужно сказать о развитии данной технологии – enhanced IRF (eIRF). eIRF позволяет построить более иерархичную структуру, включающую два уровня – ядро и уровень доступа (используется архитектура Clos).
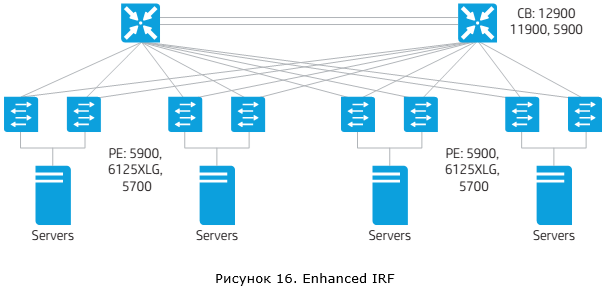
Коммутаторы, находящиеся на уровне ядра (уровень Spine для архитектуры Clos), будут выполнять функции управления (такие коммутаторы называются Controlling Bridges — CB). И фактически стек IRF запускается именно на них. Коммутаторы, находящиеся на уровне доступа (уровень Leaf для архитектуры Clos), будут выполнять лишь функции расширения портов и обеспечивать только передачу трафика (такие коммутаторы называются Port Extenders – PE). Коммутаторы PE (в ряде документов такие коммутаторы обозначаются аббревиатурой PEX) не имеют функций локальной коммутации и абсолютно все пакеты будут передаваться на коммутаторы ядра. На данный момент может быть два коммутатора ядра и до 30 коммутаторов уровня доступа. Все эти коммутаторы будут выглядеть как одно большое устройство. Ничего не напоминает? Конечно же, аналогичное решение у Cisco – это Instant Access.
Пример реализации технологии IRF
Давайте рассмотрим пример настройки технологии IRF.
Назначаем коммутаторам member ID. Так как по умолчанию устройства имеют member ID = 1, member ID задаём только на втором устройстве:
[Sysname2] irf member 1 renumber 2
Renumbering the member ID may result in configuration change or loss. Continue? [Y/N]:y
[Sysname2] quit
{Sysname2} reboot
Отключаем порты, которые у нас будут использоваться в IRF канале (по умолчанию они всегда выключены):
[Sysname1] interface range ten-gigabitethernet 1/0/7 to ten-gigabitethernet 1/0/8
[Sysname1-if-range] shutdown
[Sysname2] interface range ten-gigabitethernet 2/0/7 to ten-gigabitethernet 2/0/8
[Sysname2-if-range] shutdown
Закрепляем физические порты за IRF портами:
[Sysname1] irf-port 1/1
[Sysname1-irf-port2/1] port group interface ten-gigabitethernet 1/0/7
[Sysname1-irf-port2/1] port group interface ten-gigabitethernet 1/0/8
[Sysname2] irf-port 2/1
[Sysname2-irf-port2/2] port group interface ten-gigabitethernet 2/0/7
[Sysname2-irf-port2/2] port group interface ten-gigabitethernet 2/0/8
Включаем порты, которые у нас будут использоваться в IRF канале:
[Sysname1] interface range ten-gigabitethernet 1/0/7 to ten-gigabitethernet 1/0/8
[Sysname1-if-range] undo shutdown
[Sysname1-if-range] quit
[Sysname1] save
[Sysname2] interface range ten-gigabitethernet 2/0/7 to ten-gigabitethernet 2/0/8
[Sysname2-if-range] undo shutdown
[Sysname2-if-range] quit
[Sysname2] save
Активируем IRF порты:
[Sysname1] irf-port-configuration active
[Sysname2] irf-port-configuration active
После этого то устройство, которое будет ведомым, перезагрузится. Фабрика IRF собрана. Опционально настраиваем приоритет и функции MAD.
Давайте теперь посмотрим, что мы получим после объединения коммутаторов. Первый коммутатор (MemberID=1) у нас стал мастером (Master), второй коммутатор (MemberID=2) стал ведомым (Standby).
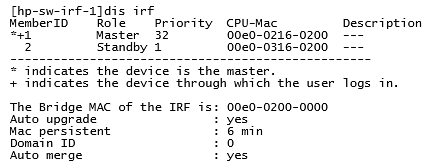
Информация по портам, которые используются для формирования IRF канала:

Информация по полученной топологии IRF:

Как мы видим, коммутаторы соединены между собой через порты IRF-Port1 на первом коммутаторе (MemberID=1) и IRF-Port2 на втором коммутаторе (MemberID=2).
Перед тем, как мы перейдём к заключительной части, хотел бы ещё раз отметить, что часть вопросов для меня остались за кадром, в особенности вопрос передачи пакетов внутри стека IRF.
Заключение
Хотел бы привести обобщающую таблицу, рассмотренных ранее технологий. Но сразу отмечу, определять «кто самый крутой в этой песочнице?» не буду. Во-первых, обе технологии являются проприетарными и по факту их использование является фактически следствием выбора того или иного вендора в качестве производителя решения для построения сетевой инфраструктуры. Во-вторых, по каждому пункту можно долго дискутировать. Например, IRF поддерживается на более широком модельном ряде. А у Cisco на младших моделях есть свои технологии стекирования. VSS поддерживает всего два коммутатора. А зачем больше? И так далее. В-третьих, я рассмотрел лишь общие функциональные моменты, оставив за кадром такие важные вопросы, как стабильность работы, удобство обслуживания, поиска проблем и пр.
| Cisco VSS | HPE IRF | |
|---|---|---|
| Где поддерживается | 4500X, 4500E, 6500E, 6800 | 3100, 3600, 5120 и т.д. |
| Количество устройств, которые можно объединить | 2 | 9 |
| Переключение с сохранением состояния | Да (SSO/NSF) | Да |
| Скорость переключения в случае отказа основного коммутатора | 200-400 мсек | 50 мсек |
| Шина для объединения коммутаторов | VSL канал, Ethernet-порты | IRF канал, Ethernet-порты |
| Технологии обнаружения ситуации с двумя активными коммутаторами | ePAgP, Fast Hello, IP BFD | LACP, BFD, ARP, ND |
| Предотвращение проблем в сети в случае разрыва VSL/IRF канала | Блокировка портов | Блокировка портов |
| Построение иерархичных топологий | Instant Access | eIRF |
И напоследок. Никогда не стоит забывать, что один большой или не очень большой виртуальный коммутатор (он же стек) даёт нам достаточно много преимуществ, но при этом может явиться единой точной отказа.
Список литературыCisco VSS
Campus 3.0 Virtual Switching System Design Guide
Release 15.1SY Supervisor Engine 2T Software Configuration Guide, Virtual Switching Systems (VSS)
Release 15.1SY Supervisor Engine 720 Software Configuration Guide, Virtual Switching Systems (VSS)
Catalyst 4500 Series Switch Software Configuration Guide, IOS XE 3.8.0E and IOS 15.2(4)E, Virtual Switching Systems (VSS)